


Cover photo by Dominik Scythe on Unsplash
We're always making improvements to Leave Me Alone, but one thing that has stayed roughly the same since launch is the Unsubscriber Bot.
If you're not familiar, how Leave Me Alone works is that we scan your inbox and show a list of all the subscriptions that you receive. We then give you the option to unsubscribe from these by clicking a button.
The Unsubscriber Bot is the part of the system that goes off and performs the actual unsubscribes on behalf of the user when they click that beautiful unsubscribe toggle.
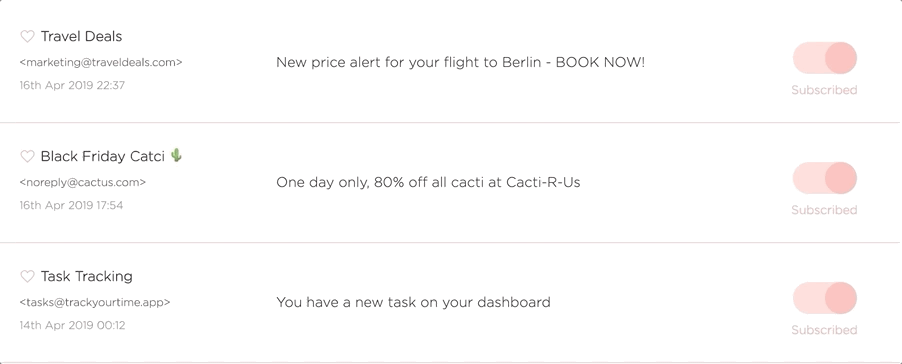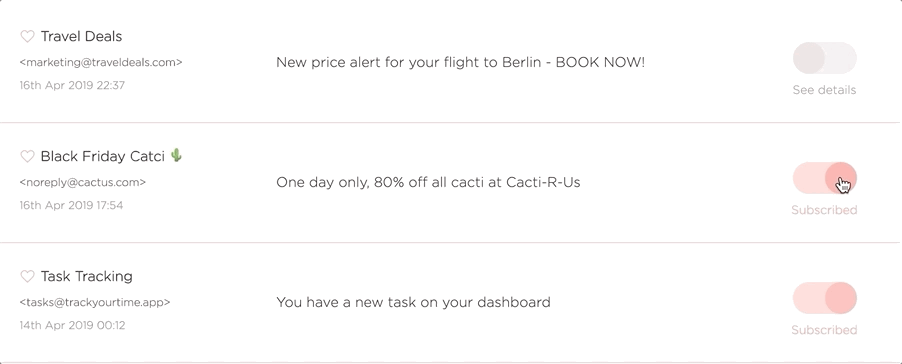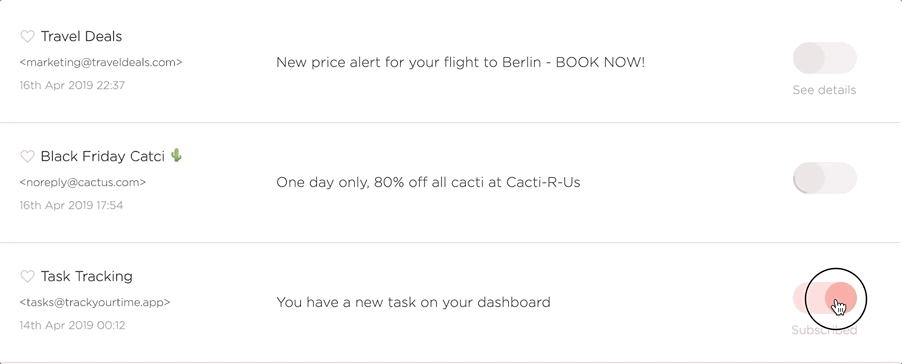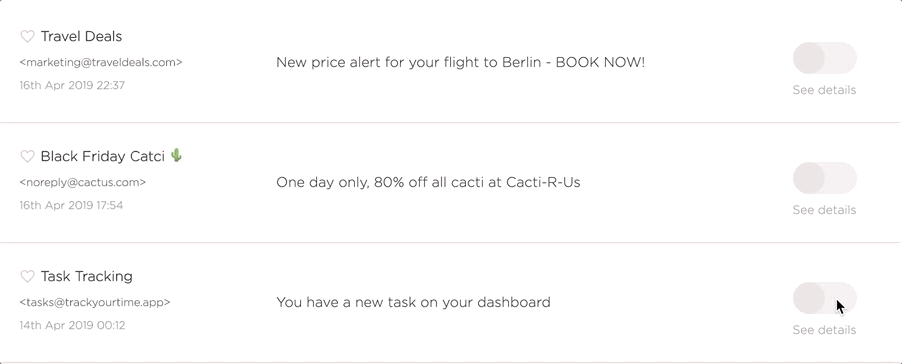
The unsubscriber is in essence quite simple, it follows a URL and reads the output, performs some actions if needed, and finally determines if the unsubscribe was successful. If it failed we tell the user and they can intervene manually.
However, when we built it we made some pretty naïve assumptions, and as we grow it's clear that these definitely need to evolve.
This article will deal one of our biggest complaints, let's see if you can figure it out from a brief description.
When performing an unsubscribe, a number of things can happen and it's up to the unsubscriber to determine if the result is a successful or not. It has a number of hard-coded basic phrases to help it to understand what is going on.
For instance if it sees the following words it knows things went well;
[
"success",
"successfully",
"unsubscribed",
"you have been removed"
]Or if it sees a button with the text Confirm then it knows to click it, and so on.
If you're a non-native English speaker then it's probably pretty obvious where I'm going with this. As I am British, of course I bore little thought to the languages that the unsubscriber would encounter when we unleashed it upon the real world, and regretfully taught my child only English.
However, unlike me it can learn from the world.
Disclaimer - I'm a web-developer, not a data-scientist. If I've used the wrong words below or said anything else stupid, please correct me and I'll make edits.
Thankfully when the unsubscriber was born I decided it would be a great idea to gather data on it's failures in case we ever needed them in the future. Although I didn't know it at the time, this is probably the best decision I've made.
After an unsubscribe (successful or not) we offer the user this screen;
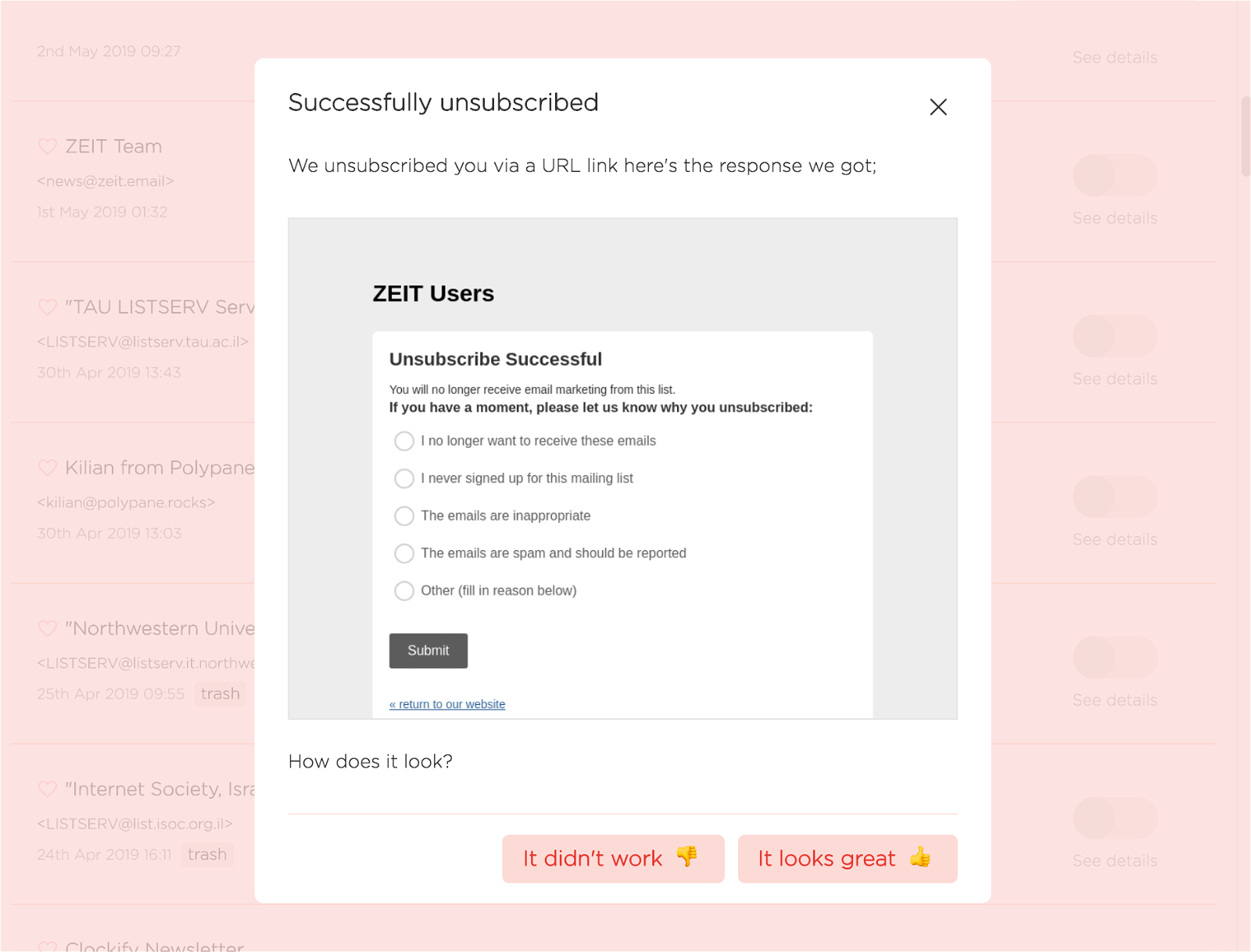
This allows us to gather information of exactly what happened. Given this beautifully rich data, surely the unsubscriber can learn something from it.
Unfortunately before we can get started we're struck with a problem, we've been saving this data as images when all we really need is the text (yeah past me is an idiot). So first we'll need to get the text out.
To grab the text from the images we'll be using OCR software Tesseract. Tesseract seems to work better when the text is bigger, so we'll also enlarge the images using the popular image processor Sharp. Finally, Tesseract wont detect the language for us, so this will be the job of langdetect.
const Tesseract = require('tesseract.js');
const sharp = require('sharp');
const fs = require('fs');
const langdetect = require('langdetect');
// read all image filenames from path
const path = __dirname + '/images';
const images = fs.readdirSync(path).filter(p => p.endsWith('.png'));
let languages = {};
const { TesseractWorker } = Tesseract;
const worker = new TesseractWorker();
(async () => {
// process images one at a time
for (let i = 0; i < images.length; i = i + 1) {
const image = images[i];
await new Promise(resolve => {
// resize image
sharp(`${path}/${image}`)
.resize(1200, 900)
.toFile('output.png')
.then(() => {
worker
.recognize(`output.png`)
.progress(message => {})
.catch(err => {})
.then(result => {
// result.words stores the metadata
// dertermined anbout each bit of text
if (result.words.length) {
// use the first identified language
// and add to the count
const language = langdetect.detectOne(result.text);
console.log(language);
const currentCount = languages[language] || 0;
languages = {
...languages,
[language]: currentCount + 1
};
}
fs.writeFileSync(
'languages.json',
JSON.stringify(languages, null, 2)
);
resolve();
})
.finally(resultOrError => {});
});
});
}
})();
After a long while processing our images we have a nice overview of what languages are present.
{
en: 6438,
fr: 1153,
it: 503,
nl: 346,
...
}
But what we really want is the keywords.
From the English corpus we can tell that the most frequently used phrases are those that represent the status of the unsubscribe; "unsubscribe successful", "sorry for the inconvenience", "your email has been removed", etc. We can assume this will be the same in other languages, so even though we can't understand them we can be relatively sure of the accuracy. We are also helped by the user feedback that was provided within the app.
What we are looking for in language processing terms is the top highest occurring n-grams. An n-gram is simply a contiguous sequence of n terms, in our case "unsubscribe successful" is a bigram, and we want to determine if this occurs a lot. The higher the frequency, the more relevant that n-gram is to the action...probably.
By modifying our Tesseract script a bit we can store all the text into language files for later (this is known as a corpus).
let language;
if (result.words.length) {
// use the first identified language
// and add to the count
const language = langdetect.detectOne(result.text);
const currentCount = languages[language] || 0;
languages = {
...languages,
[language]: currentCount + 1
};
}
// add text to the corpus
fs.appendFileSync(`${__dirname}/corpus/${language}.txt`, result.text, 'utf8');
And after all the images are processed we have quite a substantial number of lines in various languages.
$ wc -l ./corpus/*
138 ./corpus/af.txt
87 ./corpus/cs.txt
492 ./corpus/da.txt
4958 ./corpus/de.txt
277388 ./corpus/en.txt
1507 ./corpus/es.txt
325 ./corpus/et.txt
130 ./corpus/fi.txt
5553 ./corpus/fr.txt
71 ./corpus/hr.txt
215 ./corpus/hu.txt
169 ./corpus/id.txt
2602 ./corpus/it.txt
17 ./corpus/lt.txt
7 ./corpus/lv.txt
1342 ./corpus/nl.txt
393 ./corpus/no.txt
755 ./corpus/pl.txt
2377 ./corpus/pt.txt
3411 ./corpus/ro.txt
258 ./corpus/sk.txt
153 ./corpus/sl.txt
902 ./corpus/so.txt
19 ./corpus/sq.txt
292 ./corpus/sv.txt
53 ./corpus/sw.txt
94 ./corpus/tl.txt
743 ./corpus/tr.txt
129 ./corpus/vi.txt
304580 totalSo lets run an n-gram frequency analysis on our new corpus. For this we're using natural language processing library natural.
const natural = require('natural');
const fs = require('fs');
const LANG = 'fr';
const text = fs.readFileSync(`${LANG}.txt`).toString();
// find ngrams of 5 words
const ngrams = natural.NGrams.ngrams(text, 5);
// count ngram occurrences
let out = ngrams.reduce((o, ng, i) => {
const str = ng.join(' ');
if (o[str]) {
return {
...o,
[str]: o[str] + 1
};
}
return { ...o, [str]: 1 };
}, {})
// sort ngrams by count
out = Object.keys(out).sort((a, b) => {
return out[a] - out[b];
}).reduce((o, key) => {
return { ...o, [key]: out[key] };
}, {})
// write sorted ngrams out to a file
fs.writeFileSync(`${LANG}.analysis.js`, JSON.stringify(out, null, 2));
Using French as an example we can see that some of the highest frequency phrases are pretty good;
[
"désabonnement réussi", // unsubscribed successfully
"vous ne recevrez plus", // you will not receive any more
...
]Unfortunately there's also a lot of garbage. A frequent screen to see after unsubscribing is the Mailchimp "why did you unsubscribe" page that looks like this.
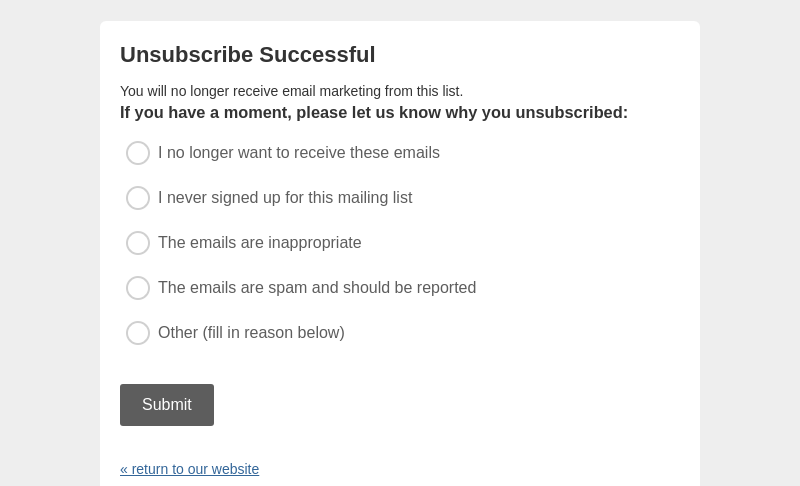
So we get a lot of phrases from screens like these, which are not very useful.
[
...
// I never subscribed to this list
"je ne suis jamais abonné à cette liste",
// if you have a moment
"Si vous avez un moment",
// why you unsubscribed
"pourquoi vous vous êtes désabonnement"
...
]
Conclusion
Despite being a fun and interesting experiment, is this better than just translating our English phrases into native terms for different languages?
Probably not.
In most languages we don't have enough data to do a decent analysis, and even in the ones prevalent enough to get enough phrases I still had to manually intervene to translate them and make sure they were valid.
So what's next?
We'll continue to work on adding multi-language support, but it's likely we will have to translate the phrases properly, not rely on automatic translation like this.
With the newest version of Leave Me Alone we will be giving users rewards for performing various actions such as referring their friends. This recent tweet by Guilherme Rizzo has got me thinking that perhaps users might be willing to provide their own translations in return for a decent enough reward.
Hello, world! 정석원 just translated CSS Scan to 🇰🇷 Korean, and @Habbe to 🇸🇪 Swedish!
— Guilherme Rizzo from CSS Scan (@gvrizzo) June 1, 2019
📊I created a simple Google Sheets where anyone can translate CSS Scan to their own language - we'll credit you on our website 👉 https://t.co/sRDLWlVM0t
👉 CSS Scan https://t.co/qmNzkkZtzS pic.twitter.com/scylVbiEZZ
Thanks for reading this far! Subscribe to our blog to see where we take this in the future and hear about other Leave Me Alone decisions and improvements!
Special thanks to my French friends Baz and Anne-Laure for double checking my phrases actually made some sense, and for teaching me some French curse words!
